
Every time you type a message into ChatGPT and hit send, somewhere in the world, a rack of GPUs lights up, fans spin, cooling systems kick in, and electricity flows. You get an answer in seconds. But the planet pays a small, invisible bill.
Most people never see that bill. There’s no energy meter next to the chat window. No water gauge. No carbon counter. The interface is clean, fast, and consequence free by design. But the consequence exists, quietly, in data centers spread across the world.
At Strancer AI Labs, we built AI Eco Impact Tracker to change that. To take the hidden cost of every AI conversation and bring it into plain sight – in real numbers, calculated from real math, displayed right inside the interface where you’re already working.
This is the story of how that math works.
Table of Contents
- Why This Matters
- The Foundation: What is a Token?
- The Engine: GPU Compute & FLOPs
- Step-by-Step: The Energy Calculation
- From Energy to Environmental Impact
- The Water Nobody Talks About
- CO₂ Emissions: The Carbon Cost
- Electricity Cost by Region
- Putting It All Together: A Real Example
- The Scale Problem
- What You Can Do
- Methodology & Assumptions
1. Why This Matters
Artificial Intelligence is no longer a niche research tool. Hundreds of millions of people use ChatGPT, Claude, Gemini, and other large language models every single day. OpenAI reportedly handles over 10 million queries per day. Each one of those queries is not free for the company, and not for the environment.
The challenge is that this cost is invisible to the user. You don’t see the electricity meter tick when you ask ChatGPT to write an email. You don’t see the water evaporating from the cooling towers of a data center in Iowa when you ask for a recipe. You don’t see the carbon dioxide entering the atmosphere when you generate a 2,000-word essay.
We built Eco Impact Tracker to make this visible. And to make it visible accurately, we had to build a mathematical model from the ground up. This blog walks you through every step of that math.
2. The Foundation: What is a Token?
Before we can calculate energy, we need to understand the atomic unit of AI computation: the token.
OpenAI explains it best on their official Tokenizer page:
“OpenAI’s large language models process text using tokens, which are common sequences of characters found in a set of text. The models learn to understand the statistical relationships between these tokens, and excel at producing the next token in a sequence of tokens.”
A token is not exactly a word. It’s a chunk of text — a fragment of characters — that the model processes as a single unit. OpenAI’s own documentation gives us the canonical rule of thumb:
“One token generally corresponds to ~4 characters of text for common English text. This translates to roughly ¾ of a word — so 100 tokens ≈ 75 words.”
Visualizing It
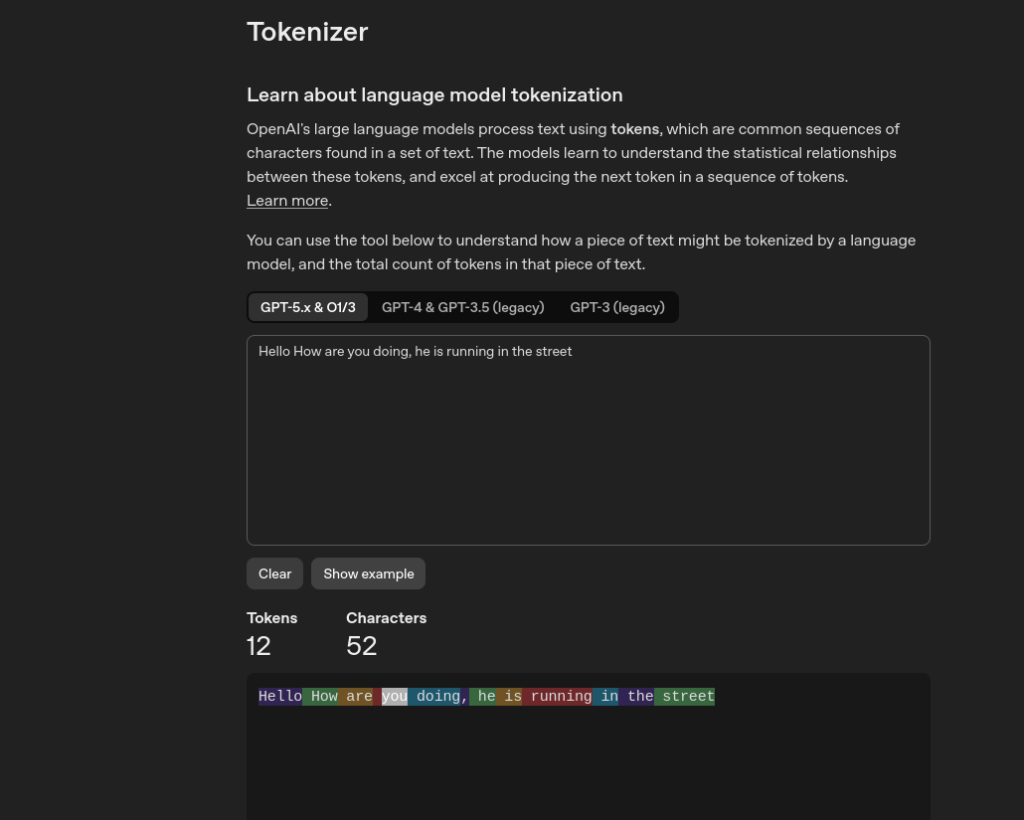
You can see this live on OpenAI’s Tokenizer tool. Type any sentence and it highlights exactly how the text is broken into tokens, coloring each one differently. It’s a surprisingly revealing exercise — common words like “the” or “is” are single tokens, while longer or unusual words can break into 2–4 tokens.
Some concrete examples:
| Text | Approximate Tokens |
|---|---|
| “What is the capital of France?” | ~8 tokens |
| A 75-word paragraph | ~100 tokens |
| A 500-word essay | ~650 – 700 tokens |
| A 2,000-word article | ~2,600 – 2,800 tokens |
Why Tokens Matter for Energy
Every single token that enters or exits a language model requires a full forward pass (or partial pass) through billions of matrix multiplications. More tokens = more compute = more electricity. The relationship is nearly linear – double the tokens, roughly double the energy.
We split tokens into two types because they have different computational costs:
- Input tokens (your prompt) – processed in the prefill phase (parallel, fast)
- Output tokens (the model’s response) – processed in the decode phase (sequential, one token at a time, slower)
We weight them differently to reflect this:
Input Token Weight = 1.2
Output Token Weight = 1.0
Input tokens get a slightly higher weight because the prefill phase, while fast, loads the entire context into GPU memory simultaneously – which is memory-bandwidth intensive. Output tokens are cheaper per-token computationally, but they’re generated one at a time, keeping the GPU occupied longer.
Weighted Tokens = (Input Tokens × 1.2) + (Output Tokens × 1.0)
Our Token Estimator
Since we can’t run OpenAI’s tiktoken tokenizer directly inside a browser extension (it’s a Python package, though a JavaScript port exists for programmatic use), we approximate token count from raw text using a blended heuristic:
Character Estimate = characters ÷ 4 (per OpenAI's official rule of thumb)
Word Estimate = words × 1.3 (accounts for subword tokenization)
Final Estimate = (Character Estimate × 0.7) + (Word Estimate × 0.3)
We weight the character-based estimate more heavily (0.7) because OpenAI’s own documentation grounds the “~4 characters per token” figure as the primary benchmark. The word estimate adds a correction for cases where tokenization fragments less common words into multiple subword tokens.
For typical English conversations, this heuristic stays within ±10–15% of the true token count – accurate enough to produce meaningful environmental estimates.
3. The Engine: GPU Compute & FLOPs
Large language models run on GPUs – specifically, for frontier models like GPT-5, on clusters of NVIDIA H100 SXM GPUs, the current industry standard for AI inference.
Here are the hardware constants we use:
| Parameter | Value | Description |
|---|---|---|
P_gpu | 700 W | Power draw per H100 GPU (TDP) |
GPU_TFLOPS | 2,000 TFLOPS | FP16 throughput of H100 |
U | 0.65 | GPU utilization factor (65%) |
N_gpu | 8 | GPUs per inference node |
MODEL_PARAMETERS | 1.2 × 10¹² | 1.2 Trillion parameters (fixed assumption) |
What is a FLOP?
A FLOP (Floating Point Operation) is a single arithmetic calculation – an addition or multiplication. It’s the base unit of computational work.
A TFLOP is 10¹² (one trillion) FLOPs.
The H100 can perform 2,000 TFLOPS of FP16 operations per second – that is 2 × 10¹⁵ floating point calculations every single second. It is an extraordinarily powerful chip.
The 1.2 Trillion Parameter Assumption
We fix model parameters at 1.2 trillion. This is a reasonable mid-range estimate for frontier models like GPT-4, which are widely believed to be in the range of 1–1.8 trillion parameters across mixture-of-expert architectures.
This is a static assumption. We don’t dynamically scale it per conversation because:
- The actual model size is not publicly disclosed by OpenAI
- A fixed, conservative estimate produces consistent and reproducible results
- It errs toward transparency – users understand the assumption
4. Step-by-Step: The Energy Calculation
Now we can walk through the full pipeline.
Step 1: Weighted Token Count
Weighted Tokens = (N_input × 1.2) + (N_output × 1.0)Example:
Input tokens = 150
Output tokens = 300
Weighted Tokens = (150 × 1.2) + (300 × 1.0)
= 180 + 300
= 480 weighted tokensStep 2: Total FLOPs
The fundamental formula for transformer inference FLOPs is:
FLOPs = 2 × Parameters × TokensThe factor of 2 accounts for one multiplication and one addition per parameter per token the two operations in a multiply-accumulate (MAC), which is the atomic operation in matrix multiplication.
FLOPs_total = 2 × MODEL_PARAMETERS × Weighted_TokensExample:
FLOPs_total = 2 × 1.2 × 10¹² × 480
= 2 × 5.76 × 10¹⁴
= 1.152 × 10¹⁵ FLOPs
≈ 1.152 PFLOPsThat is 1.152 quadrillion floating point operations for a single conversation of 150 input + 300 output tokens. This is not a typo.
Step 3: Effective GPU Throughput
We calculate how fast the GPU cluster can process those FLOPs:
GPU_FLOPS_PER_SEC = GPU_TFLOPS × 10¹² × U × N_gpuExample:
GPU_FLOPS_PER_SEC = 2000 × 10¹² × 0.65 × 8
= 1.04 × 10¹⁶ FLOPs/secondStep 4: Compute Time (Implicit)
compute_seconds = FLOPs_total ÷ GPU_FLOPS_PER_SECExample:
compute_seconds = 1.152 × 10¹⁵ ÷ 1.04 × 10¹⁶
≈ 0.1108 seconds
≈ 110.8 millisecondsThis is consistent with real-world latency observations for ChatGPT responses.
Step 5: GPU Energy Consumption
E_gpu_kWh = (P_gpu × N_gpu × compute_seconds) ÷ 3,600,000The denominator converts watt-seconds (joules) to kilowatt-hours. 1 kWh = 3,600,000 watt-seconds
Example:
E_gpu_kWh = (700 × 8 × 0.1108) ÷ 3,600,000
= 620.48 ÷ 3,600,000
= 1.724 × 10⁻⁴ kWh
= 0.0001724 kWh
= 0.1724 WhStep 6: Total Datacenter Energy (PUE)
GPUs are not the only thing consuming power in a data center. There’s cooling, networking, lighting, UPS systems, and more. We account for this with PUE (Power Usage Effectiveness):
PUE = Total Facility Power ÷ IT Equipment PowerAn ideal data center has PUE = 1.0 (impossible in practice). World-class hyperscale data centers like those operated by Google achieve ~1.1. Industry average is ~1.5, which is what we use.
E_total_kWh = E_gpu_kWh × PUEExample:
E_total_kWh = 0.0001724 × 1.5
= 0.0002586 kWh
= 0.2586 WhSo a single conversation of 150 input + 300 output tokens consumes approximately 0.26 Wh of total data center energy.
5. From Energy to Environmental Impact
Now that we have the energy number, we can calculate three environmental outputs: water, CO₂, and electricity cost.
6. The Water Nobody Talks About
Water is the forgotten environmental cost of AI. Data centers consume water in two main ways:
- Direct cooling – evaporative cooling towers that use water to cool chilled water loops
- Indirect cooling – the power plants generating electricity also consume water
We use WUE (Water Usage Effectiveness), a standard data center metric:
WUE = Water Consumed (liters) ÷ IT Equipment Energy (kWh)Industry average WUE ≈ 0.5 L/kWh for modern facilities.
Water_Liters = E_total_kWh × WUEExample:
Water_Liters = 0.0002586 × 0.5
= 0.0001293 liters
= 0.1293 mLThat’s 0.13 mL of water per conversation. Small, right? Now multiply by 10 million queries per day:
10,000,000 × 0.1293 mL = 1,293,000 mL = 1,293 liters per day
ChatGPT collectively consumes over 1,200 liters of water every single day — just for cooling — based on this estimate. Over a year, that’s nearly half a million liters.
7. CO₂ Emissions: The Carbon Cost
Electricity generation produces CO₂. How much depends on the carbon intensity of the local power grid the grams of CO₂ emitted per kilowatt-hour of electricity produced.
We use a global average of 0.4 kg CO₂/kWh (400g/kWh), which reflects the US average grid mix.
CO2_kg = E_total_kWh × Carbon_Intensity
CO2_grams = CO2_kg × 1000
Example:
CO2_kg = 0.0002586 × 0.4
= 0.00010344 kg
CO2_grams = 0.00010344 × 1000
= 0.1034 grams
= 103.4 mg
So a single 150-in / 300-out token conversation emits approximately 0.1 grams of CO₂.
Context: How Big Is 0.1g of CO₂?
- A single Google search emits ~0.2g CO₂
- Sending one email emits ~4g CO₂
- Driving a petrol car 1 km emits ~120g CO₂
- One hour of video streaming emits ~36g CO₂
Individual AI queries are small. But they accumulate rapidly with usage and at scale.
8. Electricity Cost by Region
The same computation costs different amounts of electricity money depending on where you are in the world. We maintain a regional rate table:
| Region | Rate (per kWh) | Currency |
|---|---|---|
| India | ₹6.47 | Indian Rupee |
| United States | $0.176 | US Dollar |
| European Union | €0.25 | Euro |
| United Kingdom | £0.28 | Pound Sterling |
Cost = E_total_kWh × Regional_Rate
Example (India):
Cost = 0.0002586 × 6.47
= ₹0.001673
= ₹0.0017 per conversation
Example (US):
Cost = 0.0002586 × 0.176
= $0.0000455
= $0.000046 per conversation
These are the electricity costs as if you were paying the data center’s power bill for your share of the compute. They’re not what OpenAI charges — they’re the raw energy cost of the computation.
9. Putting It All Together: A Real Example
Let’s take a real-world scenario: you ask ChatGPT to explain how photosynthesis works. A decent explanation might be:
- Your prompt: 12 words ≈ 20 input tokens
- ChatGPT response: ~350 words ≈ 450 output tokens
| Step | Formula | Result |
|---|---|---|
| Weighted tokens | (20×1.2) + (450×1.0) | 474 |
| Total FLOPs | 2 × 1.2T × 474 | 1.138 PFLOPs |
| GPU throughput | 2000T × 0.65 × 8 | 10,400 TFLOPs/s |
| Compute time | 1.138P ÷ 10,400T | 109.4 ms |
| GPU energy | (700×8×0.1094) ÷ 3.6M | 0.1702 Wh |
| Total energy (PUE 1.5) | 0.1702 × 1.5 | 0.2553 Wh |
| Water consumed | 0.0002553 × 0.5 | 0.128 mL |
| CO₂ emitted | 0.0002553 × 0.4 × 1000 | 0.102 g |
| Cost (India) | 0.0002553 × 6.47 | ₹0.00165 |
| Cost (US) | 0.0002553 × 0.176 | $0.0000449 |
One question about photosynthesis costs the planet 0.128 mL of water and 0.102 grams of CO₂.
10. The Scale Problem
Individual numbers are small. That’s precisely why this cost remains invisible. But AI usage is not individual — it’s civilizational in scale.
Consider:
- 10 million ChatGPT queries/day (conservative estimate)
- Average conversation: ~500 tokens total
Daily energy = 10M × 0.22 Wh = 2,200,000 Wh = 2,200 kWh
Daily water = 10M × 0.11 mL = 1,100,000 mL = 1,100 liters
Daily CO₂ = 10M × 0.088 g = 880,000 g = 880 kg CO₂
Annual CO₂ = 880 kg × 365 ≈ 321,200 kg = 321 tonnes CO₂
321 tonnes of CO₂ per year — just from ChatGPT queries, conservatively estimated. That’s equivalent to the annual carbon footprint of about 35 average Americans.
And this is only ChatGPT. Add Claude, Gemini, Copilot, Llama deployments, and every other AI service, and the scale becomes staggering.
11. What You Can Do
Awareness is the first step. Here’s what actually reduces your AI carbon footprint:
Be concise. Shorter prompts and targeted questions use fewer tokens. A 50-token prompt uses roughly 14% less energy than a 100-token prompt for the same output.
Avoid repetition. Asking the same question twice doubles the cost. Save and reuse good responses.
Use smaller models when appropriate. GPT-4o mini, Claude Haiku, and Gemini Flash are dramatically more energy-efficient for simple tasks. Use them by default and escalate only when needed.
Time your usage. Some power grids are greener at certain times — typically during midday when solar generation peaks. Using AI during low-carbon hours reduces effective emissions.
Be intentional. Not every question needs an AI answer. Simple facts, quick calculations, and common knowledge available via a search engine are better handled that way.
12. Methodology & Assumptions
For full transparency, here are every assumption and simplification in our model:
| Assumption | Value Used | Notes |
|---|---|---|
| GPU model | H100 SXM | Industry standard for frontier inference |
| GPU power | 700W | Published TDP |
| GPU count | 8 per node | Standard DGX H100 node |
| GPU utilization | 65% | Conservative real-world estimate |
| GPU throughput | 2,000 TFLOPS | H100 FP16 spec |
| Model parameters | 1.2 trillion | Fixed estimate for frontier models |
| Input token weight | 1.2× | Higher memory bandwidth cost |
| Output token weight | 1.0× | Baseline |
| PUE | 1.5 | Industry average (not hyperscaler) |
| WUE | 0.5 L/kWh | Industry average |
| Carbon intensity | 0.4 kg CO₂/kWh | US average grid mix |
| FLOPs formula | 2 × P × T | Standard transformer inference formula |
What We Don’t Account For
- Training cost amortization — training GPT-5 consumed an estimated 50+ GWh. Spreading that across all inference queries would add a small per-query overhead.
- Network transmission — energy used to transmit your query and response over the internet.
- End device power — your laptop or phone consuming power to display the interface.
- Cooling water at the power plant — indirect water consumption from electricity generation.
- Model serving overhead — load balancers, databases, monitoring systems.
All of these would push the real-world numbers higher than our estimates. Our model is therefore conservative – a lower bound on the true environmental cost.
Closing Thoughts
The math is not meant to make you feel guilty for using AI. These tools are genuinely useful, and their benefits – in productivity, accessibility, education, and creativity – are real and significant.
The math is meant to make the cost visible. Because invisible costs don’t get optimized. They don’t get reduced. They don’t get talked about. And they don’t motivate the kind of infrastructure investment – renewable energy, more efficient chips, smarter cooling – that could bend this curve in the right direction.
Every number in Eco Impact Tracker comes from this chain of math. From your words, to tokens, to FLOPs, to watts, to liters, to grams of CO₂. A chain that connects your keyboard to the atmosphere in a way that, until now, you couldn’t see.
Now you can.
AI Eco Impact Tracker is built by Strancer AI Labs. All calculations are approximations based on publicly available industry data and standard methodologies. Actual values vary based on data center location, hardware generation, model architecture, and grid carbon intensity.
